
Interpreting and using TCP flow timing information
| Introduction | This article explains the timing information available from the ByteBlower. In particular, the focus is on the TCP. To provide a realistic network load, we'll use HTTP on top of this protocol. As will be shown below, only a small subset of the HTTP features are necessary to test the network in both directions. The relevant background for TCP and HTTP will be detailed throughout the text. As a brief introduction, for most, HTTP is the popular protocol to deliver the customer with webpages. Simplified, an HTTP client will request a web page or file stored on an HTTP server. In the next sections, we'll call this the "GET" request. The reverse direction is supported by a "PUT" request. Here, again, the HTTP client uploads data to the server. To transport these commands and payload, it relies on a lower layer TCP. It is this layer that guarantees for HTTP to reliably exchange information between end-points. Unlike its sister protocol UDP, TCP is session-oriented. As we will detail below, setting up such a session requires a number of messages to be exchanged back and forth. As can be expected, in networks with high latencies, this introduces a noticeable delay. With the ByteBlower, one is able to instrument such a TCP session at various steps in its lifetime and tune the parameters for optimal results. Although the focus of this article is on TCP, we will start with a brief introduction to HTTP. It allows us to explain the server-client model. As will be noted, the direction in which the bulk of the data flows depends on the request asked over HTTP. Almost immediately, we will expand this information into a flow diagram of the associated TCP session. Subsequent sections provide significantly more detail, they will expand the edge-cases and focus on retrieving this information through the API. |
| HTTP and TCP timing | Web traffic provides a realistic load for testing the TCP performance of a network setup. HTTP is designed around a client-server model. In the abstract it is reasonably simple: the client asks a request to a public server, and the second answers with a response. For our purposes we'll work with two types: "GET" and "PUT" requests. This essential HTTP implementation is sufficient for our purpose, of measuring the TCP performance.
Although neither is particularly difficult for our applications, at times they are the reason for the confusion: in some aspects, the requests are nearly similar, in others, they are diametrically opposed. Throughout the document, we'll keep highlighting the point of interest for that particular section. This will make the text easy to follow. |
| HTTP explained | Continuing with HTTP, all requests need the following three items:
In brief, all requests are initiated from a private client toward a public server. This initial message is short and text-based. We'll call a request large when the amount of data it refers to is large. When asked for a GET message, the server responds with the requested binary data. In the 'PUT' type, the HTTP client will append the provided data directly to the request. In the ByteBlower server, the data is generated at runtime and requires no configuration from the user. For our purposes, the specific content of the 'GET' and 'PUT' requests is outside the scope of this article. To highlight the differences between both request types, we'll itemize them below:
|
| TCP explained | The next sections provide an overview of the lifetime of a TCP session. For now, we will assume for such a session to be well-behaving, edge-cases and exceptions are kept for the next chapter. The focus of this text is on TCP events, thus details from the above-listed HTTP GET and PUT requests are kept to a minimum. As we omitted the request, neither will we discuss the contents of the TCP messages themselves. The server is said to open the TCP session passively: it is waiting for clients to make a connection. Thus for both HTTP request types listed above, the client will actively initiate the TCP session. Opening such a TCP session starts with a three-way handshake. Both client and server need to open their end of the communication and each needs to acknowledge the other end. Unlike the description might hint to, only three messages need to be exchanged. The first is a TCP message with the SYN flag enabled. This is transmitted from the HTTP client to the server. The server will respond to this message with a single TCP frame with both the ACK and SYN flags enabled. This is the SYN+ACK message. In the third and final step, the TCP client acknowledges the SYN+ACK frame of the server, with a ACK flag enabled. When an endpoint has its outgoing SYN message acknowledged, it enters the established state. As we'll expand in the next section, one should expect the HTTP client to enter this state before the HTTP server. End-points in this state can exchange data. Various algorithms do manage how and when a TCP frame with payload can be sent across. This topic is left for other articles. Finally, closing a TCP session follows a pattern similar to opening the connection. In the case of HTTP, the server will end the session by sending a TCP frame with a 'FIN' flag. The client acknowledges this FIN flag and closes its side by also enabling this flag in its response. This last FIN message will be subsequently acknowledged by the closing end. |
| Putting it together | Putting all elements together, below one finds the communication diagram of both an HTTP GET and an HTTP PUT request. The focus is on the interaction between TCP end-points. As can be seen, both requests are nearly symmetric. The interaction between OSI layers 5 (HTTP) and layer 4 (TCP) is shown on the pair of vertical lines. Lower OSI layers (e.g. IP) are omitted to increase clarity The rest of this article explains the actions on these time-axis are actually used for TCP timing in ByteBlower:
|
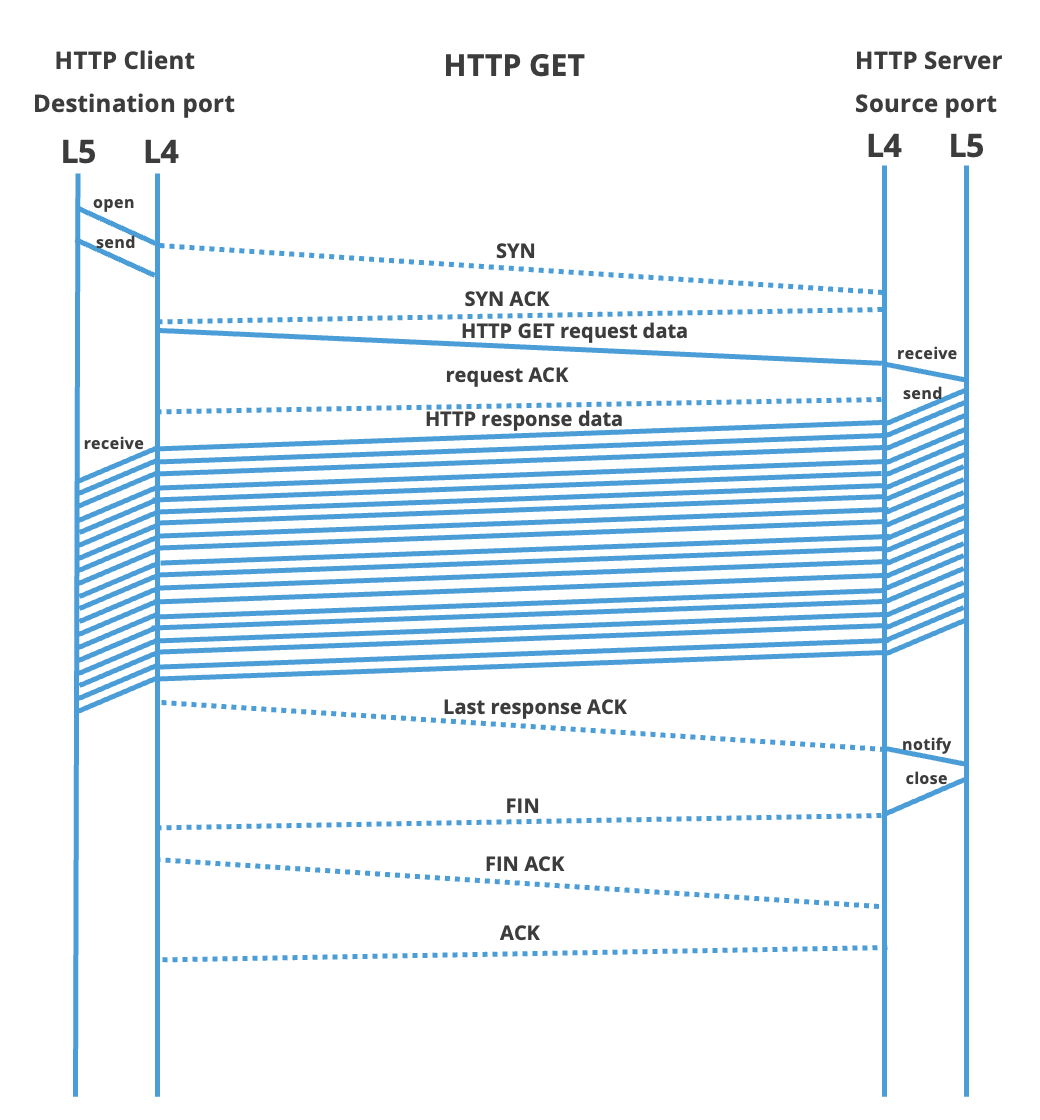
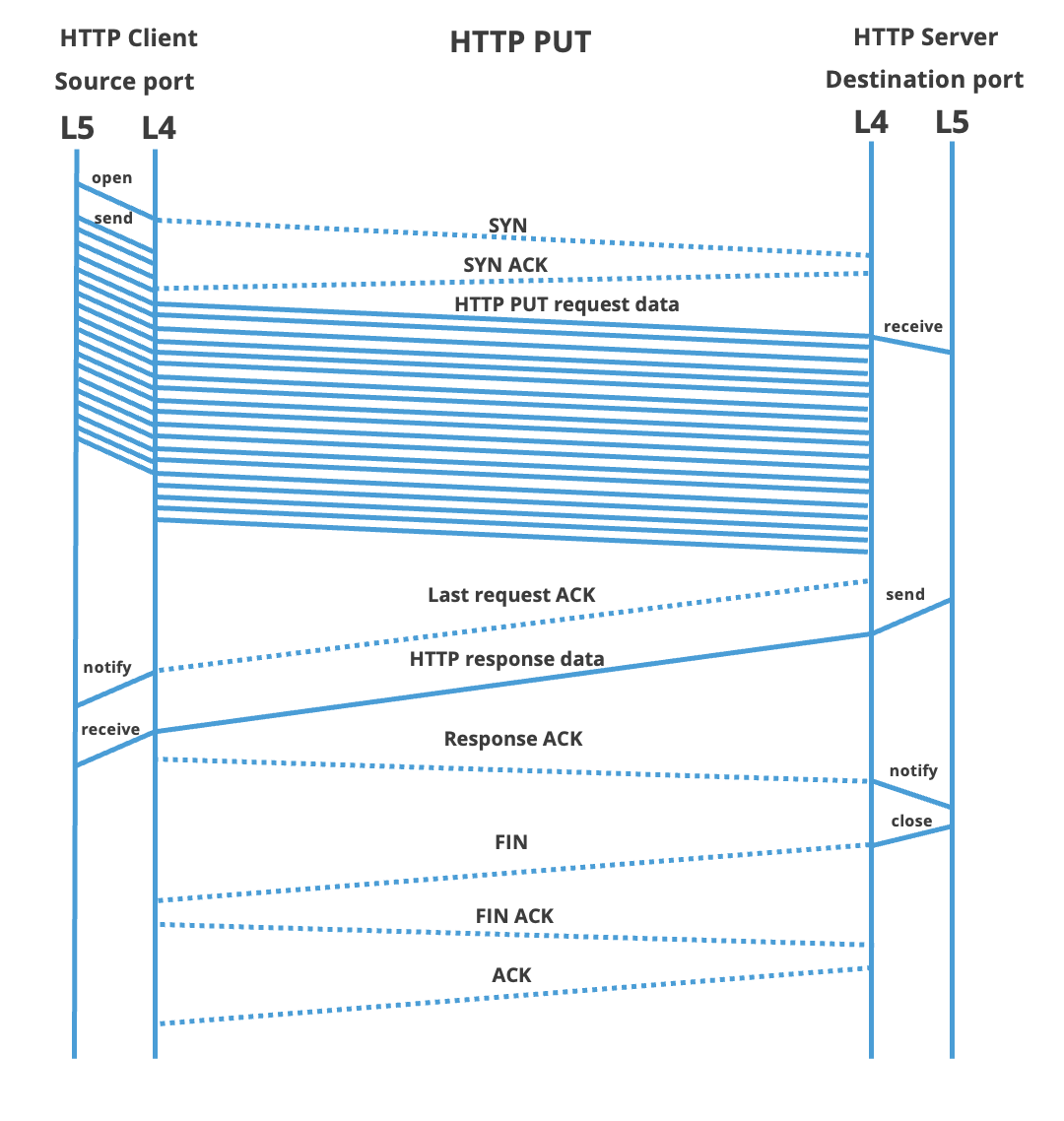
| HTTP impact | The interesting time points on the layer 5 HTTP protocol are (in order of occurrence):
Each HTTP request runs through the states as shown in the above diagram. The moment of transition is of course highly dependent on network load and other contexts. Even when multiple connections are started simultaneously one should not assume for each to run in lock-step with the others. The sections below will focus on querying the relevant information. Multiple streams can be compared using their timestamp. |
Next: 📄 Timing and automation